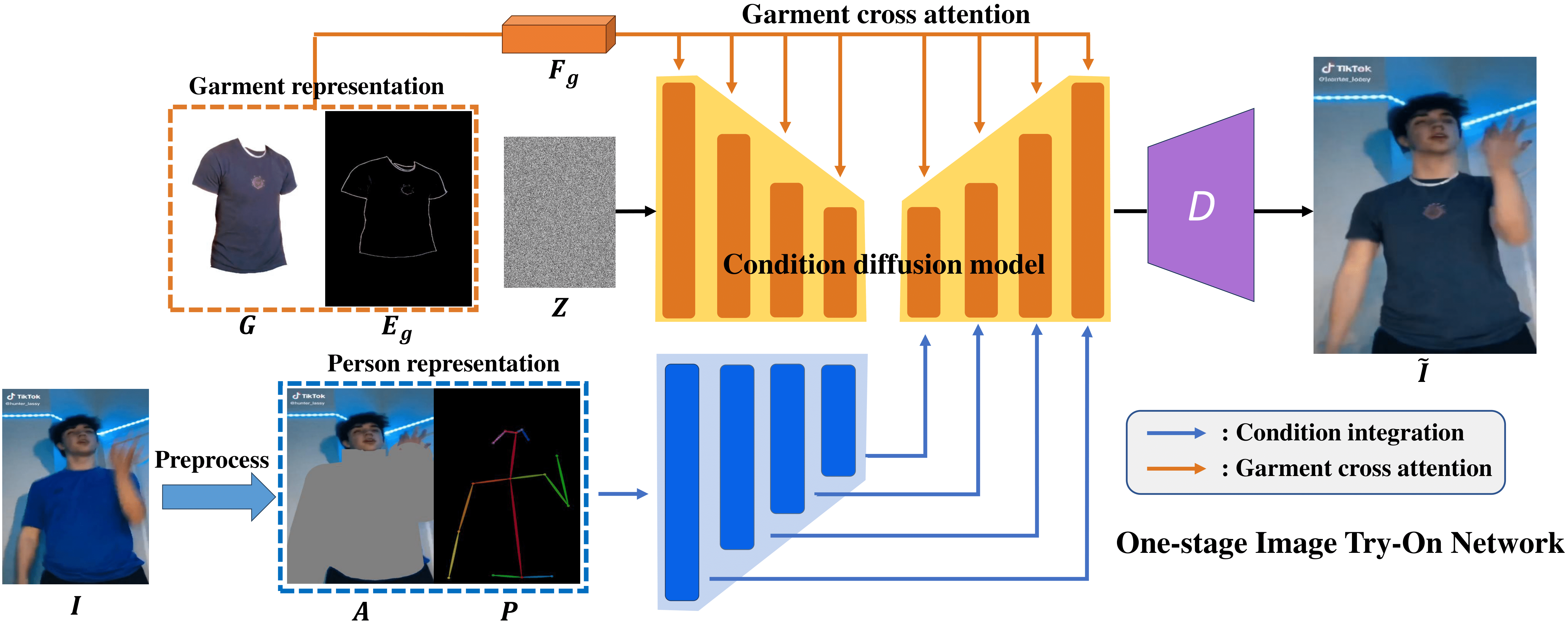
WildVidFit Framework
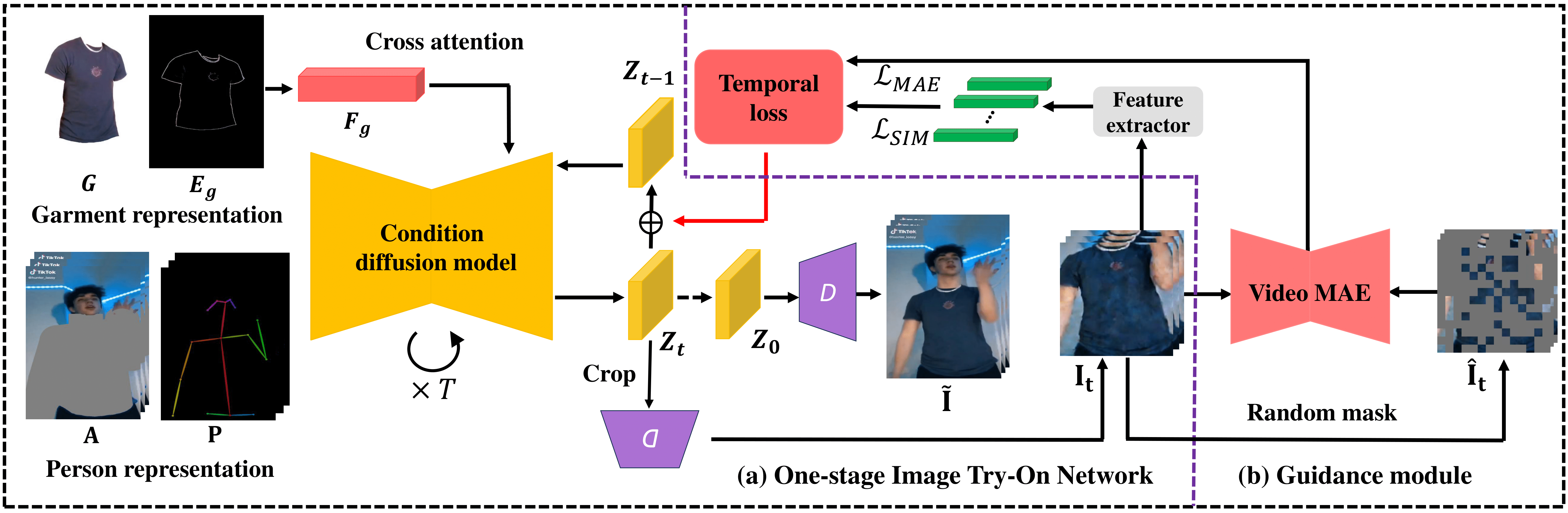
Overview of our WildVidFit framework. Our method contains two modules, i.e., a one-stage image try-on network and a guidance module. In timestep \( t\), we crop the garment area and decode the latent \(Z_t\) into sequence \(\mathbf{I_t}\). Between adjacent frames \(I^{j+1}_t\) and \(I^j_t\), the similarity loss \(L_{SIM}\) is calculated using cosine distance. Additionally, we randomly mask the sequence \(\mathbf{I_t}\) into \(\hat{\mathbf{I}}_t\), which is then inputted into VideoMAE for reconstruction. \(L_{MAE}\) represents the distance between the sequences \(\mathbf{I_t}\) and \(\hat{\mathbf{I}}_t\). We assume that a lower reconstruction loss will result in a smoother sequence. \(L_{SIM}\) and \(L_{MAE}\) together constitute the temporal loss, which controls the sampling process from \(Z_t\) to \(Z_{t-1}\).